ETLX
A modern, composable ETL / ELT framework built for data engineers. Build simpler, faster, and more maintainable data pipelines — without heavy orchestration platforms or vendor lock-in.
Open Source • MIT Licensed • DuckDB-powered
Why ETLX?
Modern data stacks are powerful — but often overcomplicated. ETLX focuses on clarity, composability, and observability, giving engineers full control over data pipelines.
Code-First & Declarative
Define what should happen, not how. ETLX pipelines are configuration-driven, version-controlled, and fully reproducible.
DuckDB at the Core
SQL-first transformations, in-process analytics, and efficient joins across files, APIs, and databases — powered by DuckDB.
Multi-Engine by Design
Run pipelines on DuckDB, PostgreSQL, SQLite, MySQL, SQL Server, or any engine supported via ODBC or DuckDB extensions.
Local-First, Production-Ready
Iterate fast locally, run in CI, containers, or cloud. No separate “dev vs prod” pipeline definitions.
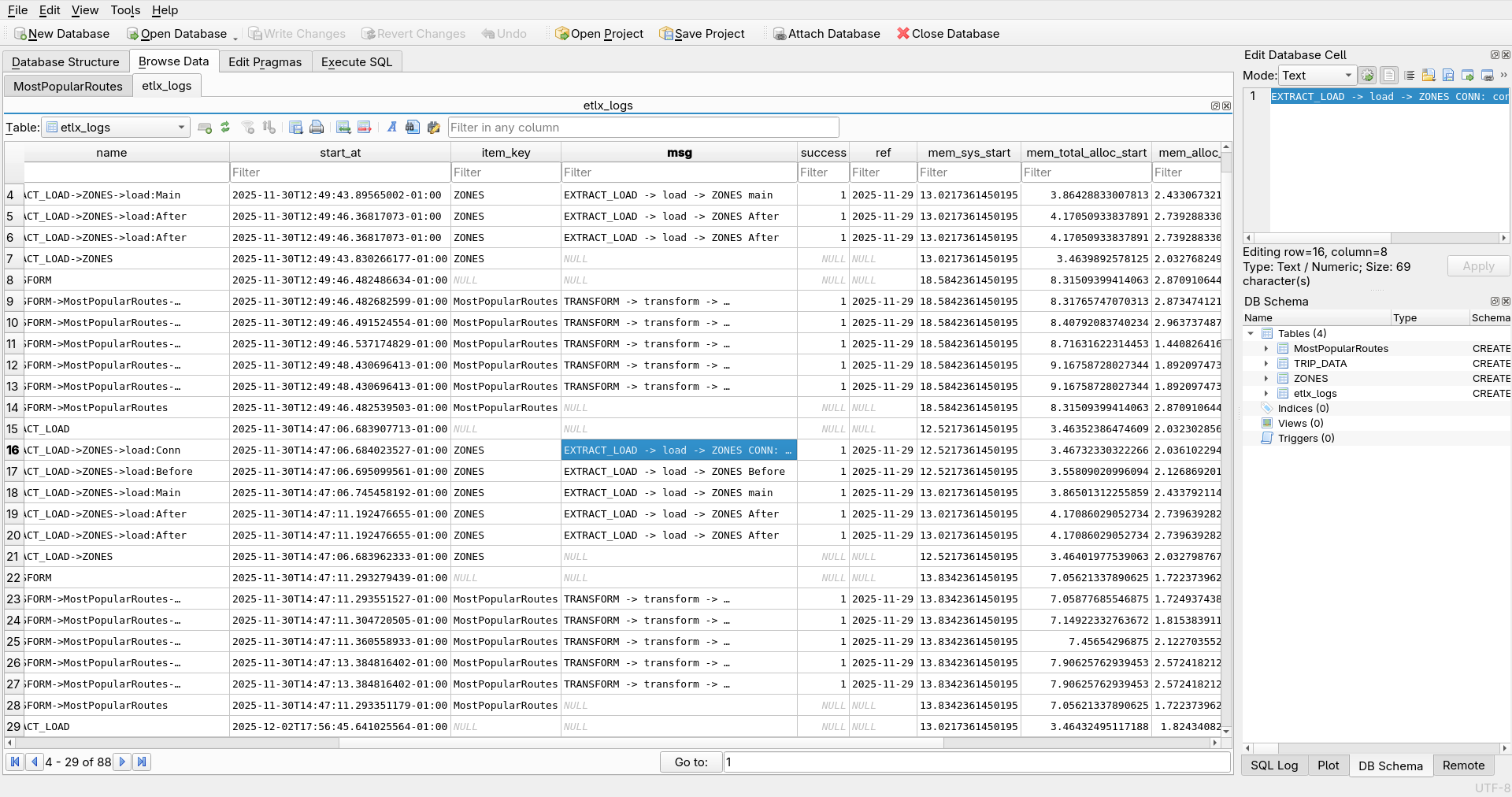
Fully Observable Execution
Every run captures timings, validations, warnings, failures, retries, and execution context — automatically and transparently.
Metadata-Driven
Pipelines are structured metadata documents that double as living documentation, lineage sources, and governance artifacts.
Self-Documenting Pipelines
Generate documentation, lineage, data dictionaries, and SQL explanations directly from pipeline definitions.
Beyond ETL / ELT
Use ETLX for reporting, regulatory documents, structured exports, and templated outputs — all from the same pipeline.
Built for Engineers
No black boxes. No hidden state. Debuggable, inspectable, and deterministic execution by design.
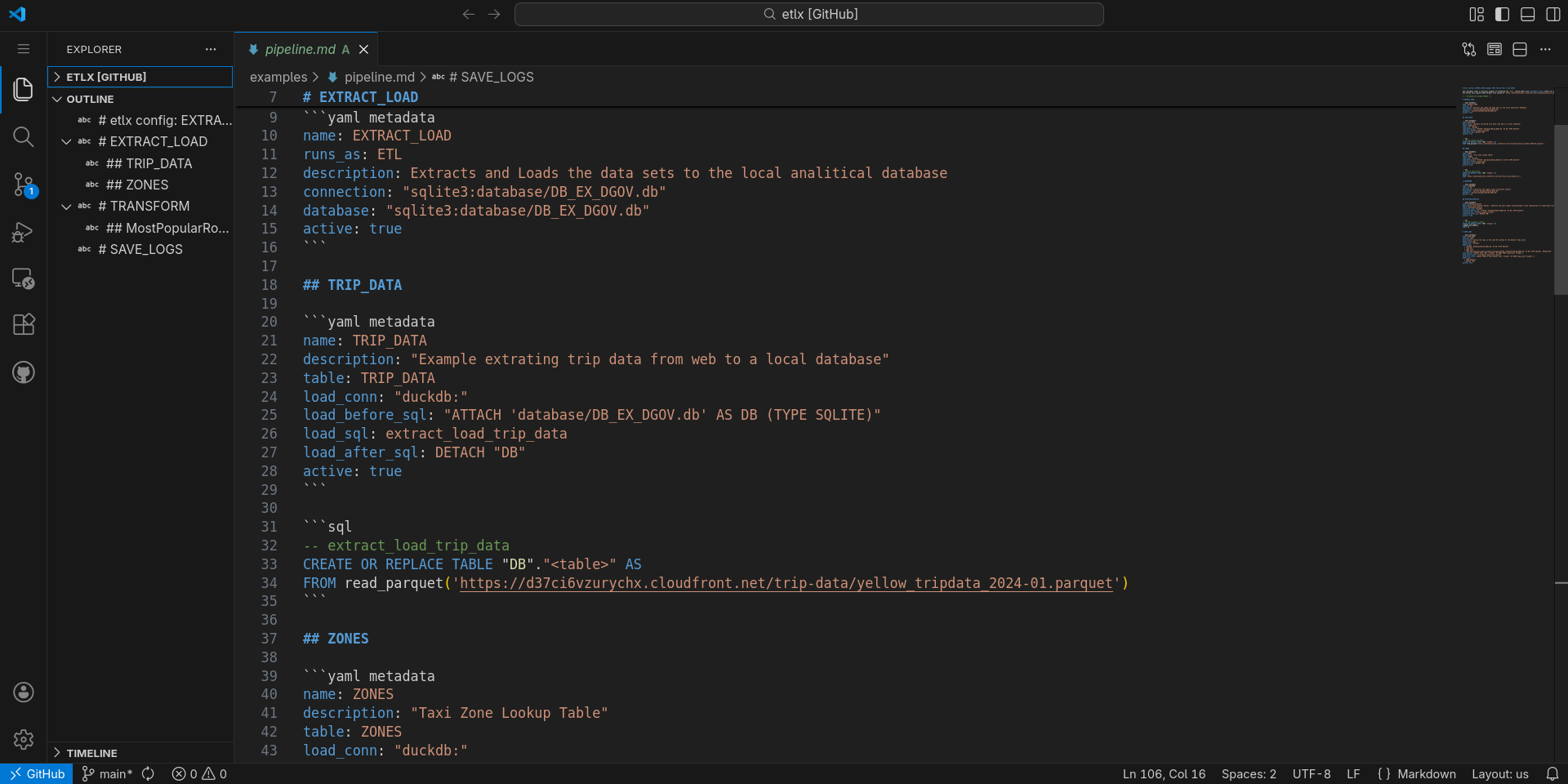
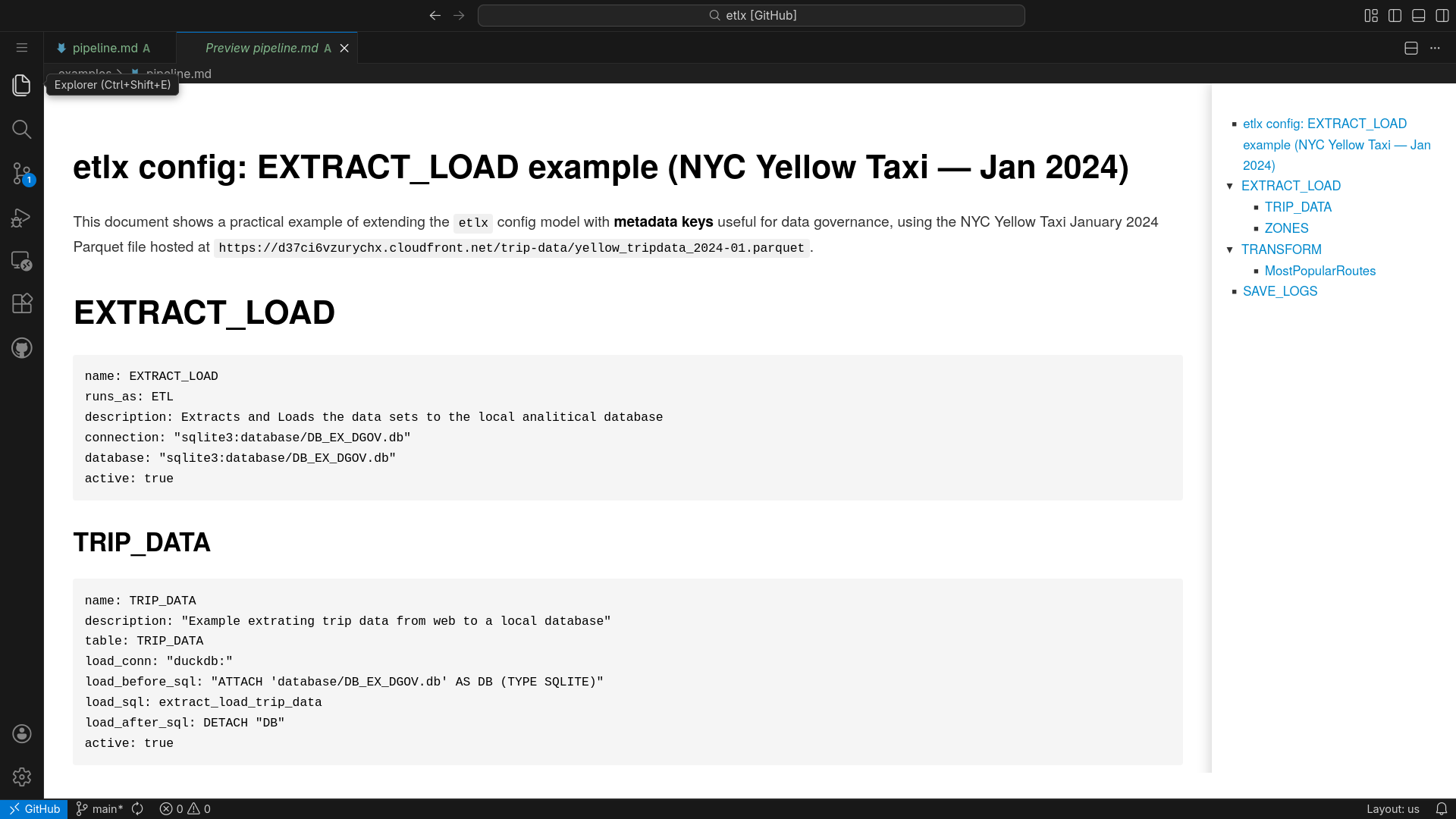
From Configuration to Execution & Documentation
ETLX treats configuration as executable documentation. The same pipeline definition powers execution, observability, lineage, and reporting.